机器学习 - 数据分布
数据分布(Data Distribution)
在本教程稍早之前,我们仅在例子中使用了非常少量的数据,目的是为了了解不同的概念。
在现实世界中,数据集要大得多,但是至少在项目的早期阶段,很难收集现实世界的数据。
我们如何获得大数据集?
为了创建用于测试的大数据集,我们使用 Python 模块 NumPy,该模块附带了许多创建任意大小的随机数据集的方法。
实例
创建一个包含 250 个介于 0 到 5 之间的随机浮点数的数组:
import numpy x = numpy.random.uniform(0.0, 5.0, 250) print(x)
直方图
为了可视化数据集,我们可以对收集的数据绘制直方图。
我们将使用 Python 模块 Matplotlib 绘制直方图:
实例
绘制直方图:
import numpy import matplotlib.pyplot as plt x = numpy.random.uniform(0.0, 5.0, 250) plt.hist(x, 5) plt.show()
结果:
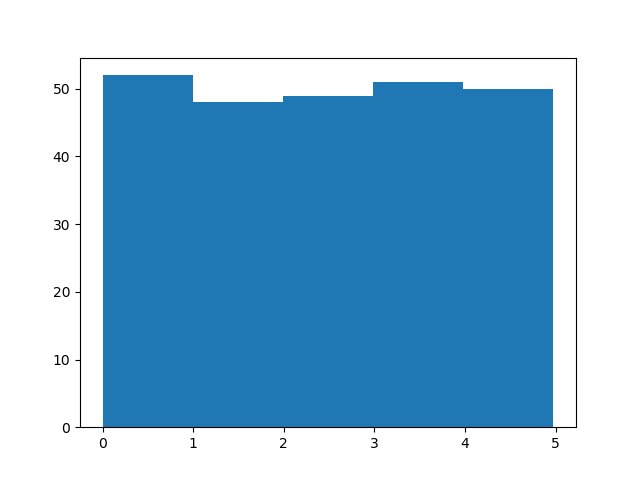
直方图解释
我们使用上例中的数组绘制 5 条柱状图。
第一栏代表数组中有多少 0 到 1 之间的值。
第二栏代表有多少 1 到 2 之间的数值。
等等。
我们得到的结果是:
52 values are between 0 and 1 48 values are between 1 and 2 49 values are between 2 and 3 51 values are between 3 and 4 50 values are between 4 and 5
注意:数组值是随机数,不会在您的计算机上显示完全相同的结果。
大数据分布
包含 250 个值的数组被认为不是很大,但是现在您知道了如何创建一个随机值的集,并且通过更改参数,可以创建所需大小的数据集。
实例
创建一个具有 100000 个随机数的数组,并使用具有 100 栏的直方图显示它们:
import numpy import matplotlib.pyplot as plt x = numpy.random.uniform(0.0, 5.0, 100000) plt.hist(x, 100) plt.show()